今回はクレジットカード比較サイトのトップページに出現する単語の出現数を調査してみたいと思います。
今回の作業にあたっては、ざっくりと以下のような技術要素が登場します。
- WEBスクレイピング
- 形態素解析による単語の分解
- 集計
実際にpythonでやる場合の手順を整理すると以下のような流れになります。
- WEBスクレイピングにより、テキストデータの取得
- 形態素解析により単語に分解
- 文から不要な文字を削除
- 文を単語ごとに分割
- 単語を正規化し、必要な単語のみを取得
- 単語の原型に変換
- リストに変換する。
- 助詞などの不要な単語を除外(ストップワードの除外)
- カウント実行
また、今回の記事ではふれませんが、今回用いた処理を前処理として、トピックモデルによる解析を最終目標としています。
ゴールの確認
最終的には単語を集計することになりますが、集計はpythonのリスト形式で集計します。
pythonでリストの数を数える関数が用意されています。
list = ['a', 'a', 'a', 'a', 'b', 'c', 'c']
print(list)
#7
print(list.count('a'))
#4
※参考:https://note.nkmk.me/python-collections-counter/
この例からわかるように、単語数を数えるためには、listのように、出現する単語をリストとして作成して上げればよいということがわかります。
今回の記事ではスクレイピングによって取得した文章を単語に分解する作業をメインに行っていきます。
形態素解析
今回のソースコードはこちらの記事をベースに作成しています。
ここでは以下の部分を実装します。
2.形態素解析により単語に分解
-文から不要な文字を削除
-文を単語ごとに分割
-単語を正規化し、必要な単語のみを取得
-単語の原型に変換
3.リストに変換する。
4.助詞などの不要な単語を除外(ストップワードの除外)
from pathlib import Path
from janome.charfilter import *
from janome.analyzer import Analyzer
from janome.tokenizer import Tokenizer
from janome.tokenfilter import *
from gensim import corpora
data_dir_path = Path('.')
corpus_dir_path = Path('.')
file_name = 'scraping_otocre.txt'
with open(data_dir_path.joinpath(file_name), 'r', encoding='utf-8') as file:
texts = file.readlines()
texts = [text_.replace('\n', '') for text_ in texts]
# janomeのAnalyzerを使うことで、文の分割と単語の正規化をまとめて行うことができる
# 文に対する処理のまとめ
char_filters = [UnicodeNormalizeCharFilter(), # UnicodeをNFKC(デフォルト)で正規化
RegexReplaceCharFilter('\(', ''), # (を削除
RegexReplaceCharFilter('\)', '') # )を削除
]
# 単語に分割
tokenizer = Tokenizer()
#
# 名詞中の数(漢数字を含む)を全て0に置き換えるTokenFilterの実装
#
class NumericReplaceFilter(TokenFilter):
def apply(self, tokens):
for token in tokens:
parts = token.part_of_speech.split(',')
if (parts[0] == '名詞' and parts[1] == '数'):
token.surface = '0'
token.base_form = '0'
token.reading = 'ゼロ'
token.phonetic = 'ゼロ'
yield token
#
# ひらがな・カタガナ・英数字の一文字しか無い単語は削除
#
class OneCharacterReplaceFilter(TokenFilter):
def apply(self, tokens):
for token in tokens:
# 上記のルールの一文字制限で引っかかった場合、その単語を無視
if re.match('^[あ-んア-ンa-zA-Z0-9ー]$', token.surface):
continue
yield token
# 単語に対する処理のまとめ
token_filters = [NumericReplaceFilter(), # 名詞中の漢数字を含む数字を0に置換
CompoundNounFilter(), # 名詞が連続する場合は複合名詞にする
# POSKeepFilter(['名詞', '動詞', '形容詞', '副詞']), # 名詞・動詞・形容詞・副詞のみを取得する
POSKeepFilter(['名詞']), # 名詞のみを取得する
LowerCaseFilter(), # 英字は小文字にする
OneCharacterReplaceFilter() # 一文字しか無いひらがなとカタガナと英数字は削除
]
analyzer = Analyzer(char_filters, tokenizer, token_filters)
tokens_list = []
raw_texts = []
for text in texts:
# 文を分割し、単語をそれぞれ正規化する
text_ = [token.base_form for token in analyzer.analyze(text)]
if len(text_) > 0:
tokens_list.append([token.base_form for token in analyzer.analyze(text)])
raw_texts.append(text)
# 正規化された際に一文字もない文の削除後の元テキストデータ
raw_texts = [text_+'\n' for text_ in raw_texts]
with open(data_dir_path.joinpath(file_name.replace('.txt', '_cut.txt')), 'w', encoding='utf-8') as file:
file.writelines(raw_texts)
# 単語リストの作成
words = []
for text in tokens_list:
words.extend([word+'\n' for word in text if word != ''])
with open(corpus_dir_path.joinpath(file_name.replace('.txt', '_word_list.txt')), 'w', encoding='utf-8') as file:
file.writelines(words)
# 単語リストからストップワードを削除
## ストップワードファイルからの呼び込み
stop_words = []
path = 'stopwords_jp.txt'
with open(path) as f:
stop_words = f.readlines()
## ストップワードの除外
changed_words = [word for word in words if word not in stop_words]
print('-----------------')
print('Delited ' + str(len(words) - len(changed_words)) + ' words' )
print('-----------------')
with open(corpus_dir_path.joinpath(file_name.replace('.txt', '_word_list_exclude.txt')), 'w', encoding='utf-8') as file:
file.writelines(changed_words)
ストップワードはこちらがよく使われているようですが、あまりにも貧相で、使いものにはなりませんでした。
Slothlib
上記の実装でも利用していますが、現実的に取得する品詞を名詞のみに絞ることで対応しました。
集計
5.カウント実行
import collections
# 集計方法1
# f = open('scraping_otocre_word_list_exclude.txt')
# data = f.read() #ファイルを文字列として取得
#
# 集計 ※dict型を定義してgetメソッドで数える。
# words = {}
# for word in data.split():
# words[word] = words.get(word, 0) + 1
# 集計方法2 内包表現を使用
path = 'scraping_otocre_word_list_exclude.txt'
with open(path) as f:
words = [s.strip() for s in f.readlines()]
# 集計処理
## count()を使用
# d = [(v,k) for k,v in words.items()]
# d.sort()
# d.reverse()
# for count, word in d[:10]:
# print(count, word)
##collections.Counter()を使用
counter = collections.Counter(words)
for word in counter.most_common(100):
print(word)
集計方法1はコメントアウトしていますが、集計方法2の代わりにこちらを使用しても動きます。
また集計処理も、count()を利用した方法でも動きます。
集計結果
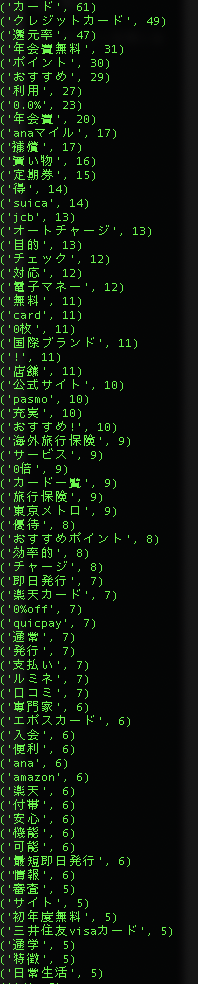
いい感じに集計が出来ました。
とはいえ、ノイズも目につきます。
“0.0%”など意味のない文字もあります。”カード”と”クレジットカード”も同じ意味ですが、どう扱うかは検討が必要です。
とりあえず、今回の解析はこれで区切りをつけたいと思います。
その他の形態素解析パッケージ
今回はJanomeというパッケージを使いましたが、有名所ではMeCabがあります。
janomeとMeCabを比較した記事もあります。
こちらの記事によると
MeCab:本格的な形態素解析におすすめ
Janome:簡単に実装、短い文章や簡易的な解析におすすめ
的なことが書いてあります。
MeCabはNeologdという単語解析の辞書の拡張が利用できます。
NEologd(mecab-ipadic-NEologd)
こちらは最新の単語が週に2回更新され優れものですが、容量はかなり食います。
必須: 空き 1.5GByte
推奨: 空き 5GByte
このあたりの形態素解析は長くなるので、別の記事で詳しく解説したいと思います。
参考サイト
Counterの使い方が紹介されている。
形態素解析のやり方が紹介されている。
その1
その2
ストップワードの削除の方法




